고정 헤더 영역
상세 컨텐츠
본문
728x90

엔티티 설계
Spring Data JPA를 사용하면 데이터베이스에 테이블을 생성하기 위해 직접 쿼리를 작성할 필요가 없다. 이 기능을 가능하게 하는 것이 엔티티이다. JPA에서 엔티티는 데이터베이스의 테이블에 대응하는 클래스이다. 엔티티에는 데이터베이스에 쓰일 테이블과 칼럼을 정의한다. 엔티티에 어노테이션을 사용하면 테이블 간 연관관계를 정의할 수 있다.
아래 테이블은 코드로 간단하게 엔티티 클래스로 구현할 수 있다. data.entity 패키지를 생성하고 그 안에 Product엔티티 클래스를 생성한다.
package com.springboot.jpa.data.entity;
import javax.persistence.*;
import java.time.LocalDateTime;
@Entity
@Table(name = "Product")
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long number;
@Column(nullable = false)
private String name;
@Column(nullable = false)
private Integer price;
@Column(nullable = false)
private Integer stock;
private LocalDateTime createdAt;
private LocalDateTime updatedAt;
...getter/setter 메서드 생략
}위와 같이 클래스를 생성하고 application.properties에 정의한 spring.jpa.hibernate.ddl-auto의 값을 create 같은 테이블을 생성하는 옵션으로 설정하면 쿼리문을 작성하지 않아도 데이터베이스에 테이블이 자동으로 만들어진다.
엔티티 관련 기본 어노테이션
엔티티를 작성할 때는 어노테이션을 많이 사용한다. 그중에는 테이블과 매핑하기 위해 사용하는 어노테이션도 있고, 다른 테이블과의 연관관계를 정의하기 위해 사용하는 어노테이션, 자동으로 값을 주입하기 위한 어노테이션도 있다. 여기서는 먼저 기본적으로 많이 사용하는 어노테이션을 소개하고, 다른 어노테이션은 이후 내용을 진행하면서 필요할 때마다 소개하겠다.
@Entity
해당 클래스가 엔티티임을 명시하기 위한 어노테이션이다. 클래스 자체는 테이블과 일대일로 매칭되며, 해당 클래스의 인스턴스는 매핑되는 테이블에서 하나의 레코드를 의미한다.
@Table
엔티티 클래스는 테이블과 매핑되므로 특별한 경우가 아니면 @Table 어노테이션이 필요하지 않다. @Table 어노테이션을 사용할 때는 클래스의 이름과 테이블의 이름을 다르게 지정해야 하는 경우다. @Table 어노테이션을 명시하지 않으면 테이블의 이름과 클래스의 이름이 동일하다는 의미이며, 서로 다른 이름을 쓰려면 @Table(name = 값) 형태로 데이터베이스의 테이블명을 명시해야 한다. 대체로 자바의 명명법과 데이터베이스가 사용하는 명명법이 다르기 때문에 자주 사용된다.
@Id
엔티티 클래스의 필드는 테이블의 칼럼과 매핑된다. @Id 어노테이션이 선언된 필드는 테이블의 기본값 역할로 사용된다. 모든 엔티티는 @Id 어노테이션이 필요하다.
@GeneratedValue
일반적으로 @Id 어노테이션과 함께 사용된다. 이 어노테이션은 해당 필드의 값을 어떤 방식으로 자동으로 생성할지 결정할 때 사용된다. 값 생성 방식은 다음과 같다.
- GeneratedValue를 사용하지 않은 방식(직접 할당)
애플리케이션에서 자체적으로 고유한 기본값을 생성할 경우 사용하는 방식
내부에 정해진 규칙에 의해 기본값을 생성하고 식별자로 사용 - Auto
@GeneratedValue의 기본 설정값
기본값을 사용하는 데이터베이스에 맞게 자동 생성한다. - IDENTITY
기본값 생성을 데이터베이스에 위임하는 방식
데이터베이스의 AUTO_INCREMENT를 사용해 기본값을 생성한다. - SEQUENCE
@SquenceGenerator 어노테이션으로 식별자 생성기를 설정하고 이를 통해 값을 자동 주입받는다.
SequenceGenerator를 정의할 때는 name, sequenceName, allocationSize를 활용한다.
@GeneratedValue에 생성기를 설정한다. - TABLE
어떤 DBMS를 사용하더라도 동일하게 동작하기를 원할 경우 사용한다.
식별자로 사용할 숫자의 보관 테이블을 별도로 생성해서 엔티티를 생성할 때마다 값을 경신하며 사용한다.
@TableGenerator 어노테이션으로 테이블 정보를 설정한다.
@Column
엔티티 클래스의 필드는 자동으로 테이블 칼럼으로 매핑된다. 그래서 별다른 설정을 하지 않을 예정이라면 이 어노테이션을 명시하지 않아도 괜찮다.
- @Column 어노테이션에서 많이 사용하는 요소는 다음과 같다.
name : 데이터베이스의 컬럼명을 설정하는 속성이다. 명시하지 않으면 필드명으로 지정된다.
nullable : 레코드를 생성할 때 칼럼 값에 null 처리가 가능하지를 명시하는 속성이다.
length : 데이터베이스에 저장하는 데이터의 최대 길이를 설정한다.
unique : 해당 컬럼을 유니크로 설정한다.
@Transient
엔티티 클래스에는 선언돼 있는 필드지만 데이터베이스에서는 필요 없을 경우 이 어노테이션을 사용해 데이터베이스에서 이용하지 않게 할 수 있다.
리포지토리 인터페이스 설계
Spring Data JPA는 JpaRepository를 기반으로 거욱 쉽게 데이터베이스를 사용할 수 있는 아키텍처를 제공한다. 스프링 부트로 JpaRepository를 상속하는 인터페이스를 생성하면 Spring Data JPA가 제공하는 다양한 메서드를 손쉽게 활용할 수
리포지토리 인터페이스 생성
여기서 이야기하는 리포지토리(Repository)는 Spring Data JPA가 제공하는 인터페이스이다. 엔티티를 데이터베이스의 테이블과 주고를 생성하는 데 사용했다면 리포지토리는 엔티티가 생성한 데이터베이스에 접근하는 데 사용된다.
public interface ProductRepository extends JpaRepository<Product, Long>{
}ProductRepository가 JpaRepository를 상속받을 때는 대상 엔티티와 기본값 타입을 지정해야 한다. 위 예제와 같이 대상 엔티티를 Product로 설정하고 해당 엔티티의 @Id 필드 타입인 Long을 설정하면 된다.
리포지토리 메서드의 생성 규칙
리포지토리에서는 몇 가지 명명규칙에 따라 커스텀 메서드도 생성할 수 있다. 일반적으로 CRUD(Create, Read, Update, Delete)에서 따로 생성해서 사용하는 메서드는 대부분 Read 부분에 해당하는 Select 쿼리밖에 없다. 엔티티를 저장하거나 갱신 또는 삭제할 때는 별도의 규칙이 필요하지 않기 때문이다. 다만 리포지토리에서 기본적으로 제공하는 조회 메서드는 기본값으로 단일 조회하거나 전체 엔티티를 조회하는 것만 지원하고 있기 때문에 필요에 따라 다른 조회 메서드가 필요하다.
메서드에 이름을 붙일 때는 첫 단어를 제외한 이후 단어들의 첫 글자를 대문자로 설정해야 JPA에서 정상적으로 인식하고 쿼리를 자동으로 만들어준다. 조회 메서드(find)에 조건을 붙일 수 있는 몇 가지 기능을 소개하면 다음과 같다.
- FindeBy : SQL문의 where 절 역할을 수행하는 구문이다. findBy 뒤에 에닡티의 필드값을 입력해서 사용한다.
예) findByName(String name) - AND, OR : 조건을 여러 개 설정하기 위해 사용한다.
예) findByNameAndEmail(String name, String email) - Like / NotLike : SQL문의 like와 동일한 기능을 수행하며, 특정 문자를 포함하는지 여부를 조건으로 추가한다. 비슷한 키워드로 Containing, Contains, isContaing이 있다.
- StartsWith / StartingWith : 특정 키워드로 시작하는 문자열 조건을 설정한다.
- EndsWith / EndingWith : 특정 키워드로 끝나는 문자열 조건을 설정한다.
- IsNull / IsNotNull : 레코드 값이 Null 이거나 Null이 나닌 값을 검색한다.
- True / False : Boolean 타입의 레코드를 검색할 때 사용한다.
- Before / After : 시간을 기준으로 값을 검색한다.
- LessThan / GreaterThan : 특정 값(숫자)을 기준으로 대소 비교를 할 때 사용한다.
- Between : 두 값(숫자) 사이의 데이터를 조회한다.
- OrderBy : SQL 문에서 order by와 동일한 기능을 수행한다.
예) 가격순으로 이름 조회를 수행한다면 List findByNameOrderByPriceAsc(String name);와 같이 작성한다. - countBy : SQL 문의 count와 동일한 기능을 수행하며, 결괏값의 개수(count)를 추출한다.
- 자세한 쿼리 메서드는 7장에서 다룬다.
DAO 설계
DAO(Data Access Object)는 데이터베이스에 접근하기 위한 로직을 관리하기 위한 객체이다. 비즈니스 로직의 동작 과정에서 데이터를 조작하는 기능은 DAO 객체가 수행한다. 다만 스프링 데이터 JPA에서 DAO의 개념은 리포지토리가 대체하고 있다.
규모가 작은 서비스에서는 DAO를 별도로 설계하지 않고 바로 서비스 레이어에서 데이터베이스에 접근해서 구현하기도 하지만, 이번 장에서는 DAO를 서비스 레이어와 리포지토리의 중간 계층을 구성하는 역할로 사용할 예정이다. 이 책에서는 간단한 데이터베이스 호출만 다루고 있기 때문에 큰 의미는 없지만 실제로 업무에 필요한 비즈니스 로직을 개발하다 보면 데이터를 다루는 중간 계층을 두는 것이 유지보수 측면에서 용이한 경우가 많다. 물론 서비스 레이어에서 리포지토리의 메서드를 호출하고 그 결과에 대해 처리할 수 있지만 비즈니스 로직을 수행하는 과정에서 데이터베이스에 관한 작업을 처리하는 것은 기능을 분리하고 관리하기에 좋은 코드라고 보기 어렵다.
객체지향적인 설계에서는 서비스와 비즈니스 레이러를 분리해서 서비스 레이어에서는 서비스 로직을 수행하고 비즈니스 레이어에서는 비즈니스 로직을 수행해야 한다는 의견도 많다. 그러나 이번 장에서는 이런 관점은 간단하게만 다루고 서비스 객체가 비즈니스 로직까지 포함하는 방향으로 진행하겠다. 도메인(엔티티) 객체를 중심으로 다뤄지는 로직은 비즈니스 로직으로 볼 수 있다.
📌 DAO vs. 리포지토리
DAO와 리포지토리는 역할이 비슷하다. 그렇기 때문에 아직도 DAO와 리포지토리를 비교하거나 어떤 차이가 있는지 논쟁하는 경우가 많다. 실제로 리포지토리는 Spring Data JPA에서 제공하는 기능이기 때문에 기존의 스프링 프레임워크나 스프링 MVC의 사용자는 리포지토리라는 개념을 사용하지 않고 DAO 객체로 데이터베이스에 접근했다. 이런 측면에서 각 컴포넌트의 역할을 고민하는 시간을 가져보면 좋을 것 같다.
DAO 클래스 생성
DAO 클래스는 일반적으로 ‘인터페이스-구현체’ 구성으로 생성한다. DAO 클래스는 의존성 결합을 낮추기 위한 디자인 패턴이며, 서비스 레이어에 DAO 객체를 주입받을 때 인터페이스를 선언하는 방식으로 구성할 수 있다. data.dao.impl 구조로 패키지를 생성한 후 dao 패키지를 생성한 후 impl 패키지에 각각 ProductDAO 인터페이스와 ProductDAOImpl 클래스를 생성한다.
다음으로 인터페이스를 구성한다. 우선 기본적인 CRUD를 다루기 위해 아래와 같이 인터페이스에 메서드를 정의한다.
package com.springboot.jpa.data.dao;
import com.springboot.jpa.data.entity.Product;
public interface ProductDAO {
Product insertProduct(Product product);
Product selectProduct(Long number);
Product updateProductName(Long number, String name) throws Exception;
void deleteProduct(Long number) throws Exception;
}일반적으로 데이터베이스에 접근하는 메서드는 리턴 값으로 데이터 객체를 전달한다. 이때 데이터 객체를 엔티티 객체로 전달할지, DTO 객체로 전달할지에 대해서는 개발자마다 의견이 분분하다. 일반적인 설계 원칙에서 엔티티 객체는 데이터베이스에 접근하는 계층에서만 사용하도록 정의한다. 다른 계층으로 데이터를 전달할 때는 DTO 객체를 사용한다. 그러나 이 부분은 회사나 부서마다 경해 차이가 있으므로 각자 정해진 원칙에 따라 진행하는 것이 좋다.
인터페이스의 설계를 마쳤다면 해당 인터페이스의 구현체를 만들어야 한다. 우선 기능 구현을 위해 아래와 같은 구현체 클래스를 작성한다.
@Component
public class ProductDAOImpl implements ProductDAO {
private final ProductRepository productRepository;
@Autowired
public ProductDAOImpl(ProductRepository productRepository){
this.productRepository = productRepository;
}
@Override
public Product insertProduct(Product product) {
return null;
}
@Override
public Product selectProduct(Long number) {
return null;
}
@Override
public Product updateProductName(Long number, String name) throws Exception {
return null;
}
@Override
public void deleteProduct(Long number) throws Exception {
}
}위 ProductDAOImpl 클래스를 스프링이 관리하는 빈으로 등록하려면 @Component 또는 @Service 어노테이션으로 지정해야 한다. 빈으로 등록된 객체는 다른 클래스가 인터페이스를 가지고 의존성을 주입받을 때 이 구현체를 찾아 주입하게 된다.
마찬가지로 DAO 객체에서도 데이터베이스에 접근하기 위해 리포지토리 인터페이스를 사용해 의존성 주입을 받아야 한다. 리포지토리를 정의하고 생성자를 통해 의존성 주입을 받으면 된다.
이제 인터페이스에 정의한 메서드를 구현해야 한다. 먼저 insertProduct() 메서드를 구현하겠다. 이 메서드에서는 Product 엔티티를 데이터베이스에 저장하는 기능을 수행하며, 아래와 같이 작성할 수 있다.
@Override
public Product insertProduct(Product product) {
Product savedProduct = productRepository.save(product);
return savedProduct;
}다음으로 조회 메서드를 작성한다. 조회 메서드에 해당하는 selectProduct() 메서드는 아래와 같다.
@Override
public Product selectProduct(Long number) {
Product selectProduct = productRepository.getById(number);
return selectProduct;
}selectProduct() 메서드가 사용한 리포지토리의 메서드는 getById()이다. 리포지토리에서는 단건 조회를 위한 기본 메서드로 두 가지를 제공하는데, 바로 getById() 메서드와 findById() 메서드이다. 두 메서드는 조회한다는 기능 측면에서는 동일하지만 세부 내용이 다르다. 각 메서드의 자세한 설명은 다음과 같다.
- getById()
내부적으로 EntityManager 의 getReference() 메서드를 호출한다. getReference() 메서드를 호출하면 프락시 객체를 리턴한다. 실제 쿼리는 프락시 객체를 통해 최초로 데이터에 접근하는 시점에 실행된다. 이때 데이터가 존재하지 않는 경우에는 EntityNotFoundException이 발생한다. JpaRepository의 실제 구현체인 SimpleJpaRepository의 getById() 메서드는 아래와 같다. @Override public T getById(ID id) { Assert.notNull(id, ID_MUST_NOT_BE_NULL); return em.getReference(getDomainClass(), id); }- findById()
내부적으로 EntityManager의 find() 메서드를 호출한다. 이 메서드는 영속성 컨텍스트의 캐시에서 값을 조회한 후 영속성 컨텍스트에 값이 존재하지 않는다면 실제 데이터베이스에서 데이터를 조회한다. 리터턴 값으로 Optional 객체를 전달한다. SimpleJpaRepository의 findById() 메서드는 아래와 같다.조회 기능을 구현하기 위해서는 어떤 메서드를 사용하더라도 무관하다. 비즈니스 로직을 구현하는 데 적합한 방식을 선정해 활용하면 된다. @Override public Optional<T> findById(ID id) { Assert.notNull(id, ID_MUST_NOT_BE_NULL); Class<T> domainType = getDomainClass(); if(metadata == null) { return Optional.ofNullable(em.find(domainType, id)); } LockModeType type = metadata.getLockModeType(); Map<String, Object> hints = new HashMap<>(); getQueryHints().withFetchGraphs(em).forEach(hints::put); return Optional.ofNullable(type == null ? em.find(domainType, id, hints) : em.find(domainType, id, type, hints)); }
다음으로 업데이트 메서드를 구현한다. 여기서는 Product 데이터의 상품명을 업데이트하는 기능을 구현한다. 업데이트 메서드에 해당하는 updateProductName() 메서드는 아래와 같이 작성할 수 있다.
@Override
public Product updateProductName(Long number, String name) throws Exception {
Optional<Product> selectedProduct = productRepository.findById(number);
Product updatedProduct;
if(selectedProduct.isPresent()) {
Product product = selectedProduct.get();
product.setName(name);
product.setUpdatedAt(LocalDateTime.now());
updatedProduct = productRepository.save(product);
} else {
throw new Exception();
}
return updatedProduct;
}JPA에서 데이터의 값을 변경할 때는 다른 메서드와는 다른 점이 있다. JPA는 값을 갱신할 때 update라는 키워드를 사용하지 않는다. 여기서는 영속성 컨텍스트를 활용해 값을 경신하는데, find() 메서드를 통해 데이터베이스에서 값을 가져오면 가져온 객체가 영속성 컨텍스트에 추가된다. 영속성 컨텍스트가 유지되는 상황에서 객체의 값을 변경하고 다시 save() 를 실행하면 JPA에서는 더티 체크(DirtyCheck)라고 하는 변경 감지를 수행한다. SimpleJpaRepository에 구현돼 있는 save() 메서드를 살펴보면 아래와 같다.
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if(entotyInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}@Transactional 어노테이션이 선언돼 있다. 이 어노테이션이 지정돼 있으면 메서드 내 작업을 마칠 경우 자동으로 flush() 메서드를 실행한다. 이 과정에서 변경이 감지되면 대상 객체에 해당하는 데이터베이스의 레코드를 업데이트하는 쿼리가 실행된다.
다음으로 삭제 메서드를 구현한다. 삭제 메서드에 해당하는 deleteProduct() 메서드는 아래와 같다.
@Override
public void deleteProduct(Long number) throws Exception {
Optional<Product> selectedProduct = productRepository.findById(number);
if(selectedProduct.isPresent()){
Product product = selectedProduct.get();
productRepository.delete(product);
} else {
throw new Exception();
}
}데이터베이스의 레코드를 삭제하기 위해서는 삭제하고자 하는 레코드와 매핑된 영속 객체를 영속성 컨텍스트에 가져와야 한다. deleteProduct() 메서드는 findById() 메서드를 통해 객체를 가져오는 작업을 수행하고 delete() 메서드를 통해 해강 객체를 삭제하게끔 삭제 요청을 한다. SimpleJpaRepository의 delete() 메서드는 아래와 같다.
@Override
@Transactional
@SuppressWarnings("unchecked")
public void delete(T entity) {
Assert.notNull(entity, "Entity must not be null!");
if (entityInformation.isNew(entity)) {
return;
}
Class<?> type = ProxyUtils.getUserClass(entity);
T existing = (T) em.find(type, entityInformation.getId(entity));
// if the entity to be deleted doesn't exist, delete is a NOOP
if (existing == null) {
return;
}
em.remove(em.contains(entity) ? entity : em.merge(entity));SimpleJpaRepository의 delete() 메서드는 21번 줄에서 delete() 메서드로 전달받은 엔티티가 영속성 컨텍스트에 있는지 파악하고, 해당 엔티티를 영속성 컨텍스트에 영속화하는 작업을 거쳐 데이터베이스의 레코드와 매핑한다. 그렇게 매핑된 영속 객체를 대상으로 삭제 요청을 수행하는 메서드를 실행해 작업을 마치고 커밋(commit) 단계에서 삭제를 진행한다.
DAO 연동을 위한 컨트롤러와 서비스 설계
앞에서 설계한 구성 요소들을 클라이언트의 요청과 연결하려면 컨트롤러와 서비스를 생성해야 한다.
이를 위해 먼저 DAO의 메서드를 호출하고 그 외 비즈니스 로직을 수행하는 서비스 레이어를 생성한 후 컨트롤러를 생성하겠다.
서비스 클래스 만들기
서비스 레이어에서는 도메인 모델(Domain Model)을 활용해 애플리케이션에서 제공하는 핵심 기능을 제공한다. 여기서 말하는 핵심 기능을 구현하려면 세부 기능을 정의해야 한다. 세부 기능이 모여 핵심 기능을 구현하기 때문이다. 이러한 모든 로직을 서비스 레이어에서 포함하기란 쉽지 않은 일이다. 이 같은 아키텍처의 한계를 극복하기 위해 이키텍처를 서비스 로직과 비즈니스 로직으로 분리하기도 한다. 도메인을 활용한 세부 기능들을 비즈니스 레이어의 로직에서 구현하고, 서비스 레이어에서는 기능들을 종합해서 핵심 기능을 전달하도록 구성하는 경우가 대표적이다.
다만 이 책의 목적은 과도한 기능 구현보다는 어떻게 프로젝트를 구성하고 스프링 부트의 기능을 온전히 사용할 수 있는지를 고민하는 것이므로 서비스 레이어에서 비즈니스 로직을 처리하는 아키텍처로 진행한다.
서비스 객체는 DAO와 마찬가지로 추상화해서 구성한다. 아래와 같이 service 패키지와 클래스, 인터페이스를 구성한다.
서비스 인터페이스를 작성하기 전에 필요한 DTO 클래스를 생성하겠다. data 패키지 안에 dto 패키지를 생성하고 ProductDto와 ProductResponseDto 클래스를 생성한다.
public class ProductDto {
private String name;
private int price;
private int stock;
public ProductDto(String name, int price, int stock) {
this.name = name;
this.price = price;
this.stock = stock;
}
public String getName(){
return name;
}
public void setName(String name) {
this.name = name;
}
public int getPrice() {
return price;
}
public void setPrice(int price) {
this.price = price;
}
public int getStock() {
return stock;
}
public void setStock(int stock) {
this.stock = stock;
}
}public class ProductResponseDto {
private Long number;
private String name;
private int price;
private int stock;
public ProductResponseDto() {}
public ProductResponseDto(Long number, String name, int price, int stock) {
this.number = number;
this.name = name;
this.price = price;
this.stock = stock;
}
public Long getNumber() {
return number;
}
public void setNumber(Long number){
this.number = number;
}
public void setName(String name){
this.name = name;
}
public int getPrice(){
return price;
}
public void setPrice(int price){
this.price = price;
}
public int getStock(){
return stock;
}
public void setStock(int stock){
this.stock = stock;
}
}그리고 서비스 인터페이스를 작성한다. 기본적인 CRUD의 기능을 호출하기 위해 간단한 메서드를 정의하겠다. 아래와 같이 코드를 작성한다.
public interface ProductService {
ProductResponseDto getProduct(Long number);
ProductResponseDto saveProduct(ProductDto productDto);
ProductResponseDto changeProductName(Long number, String name) throws Exception;
void deleteProduct(Long number) throws Exception;
}서비스에서는 클라이언트가 요청한 데이터를 적절하게 가공헤서 컨트롤러에게 넘기는 역할을 한다. 이 과정에서 여러 메서드를 사용하는데, 지금은 간단하게 CRUD만을 구현하기 때문에 코드가 단순해 보일 수 있다.
위 코드를 보면 리턴 타입이 DTO 객체인 것을 볼 수 있다. DAO 객체에서 엔티티 타입을 사용하는 것을 고려하면 서비스 레이어에서 DTO 객체와 엔티티 객체를 각 레이어에 변환해서 전달하는 역할도 수행한다고 볼 수 있다. 다만 이 부분은 실무 환경에서 내부적으로 어떻게 정의하느냐에 따라 달라질 수 있다.
정리해보면 데이터베이스와 밀접한 관련이 있는 데이터 액세스 레이어까지는 엔티티 객체를 사용하고, 클라이언트와 가까워지는 다른 레이어에서는 데이터를 교환하는 데 DTO 객체를 사용하는 것이 일반적이다. 이 책에서 구현하는 스프링 부트 애플리케이션의 구조는 아래와 같다.
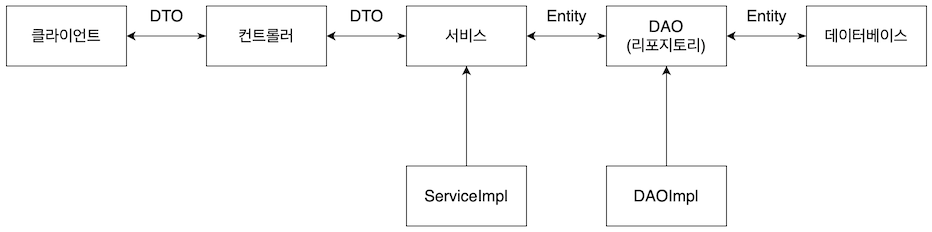
위 그림은 서비스와 DAO의 사이에서 엔티티로 데이터를 전달하는 것으로 표현했지만 회사나 개발 그룹 내 규정에 따라 DTO를 사용하기도 한다. 위 구조는 각 레이어 사이의 큰 데이터의 전달을 표현한 것이고, 단일 데이터나 소량의 데이터를 전달하는 경우 DTO나 엔티티를 사용하지 않기도 한다.
지금까지는 서비스 인터페이스를 생성했다. 이제 구현체 클래스를 작성해 보자. 구현체 클래스의 기본 형태는 아래와 같다.
@Service
public class ProductServiceImpl implements ProductService {
private final ProductDAO productDAO;
@Autowired
public ProductServiceImpl(ProductDAO productDAO) {
this.productDAO = productDAO;
}
@Override
public ProductResponseDto getProduct(Long number) {
return null;
}
@Override
public ProductResponseDto saveProduct(ProductDto productDto) {
return null;
}
@Override
public ProductResponseDto changeProductName(Long number, String name) throws Exception {
return null;
}
@Override
public void deleteProduct(Long number) throws Exception {
}
}인터페이스 구현체 클래스에서는 DAO 인터페이스를 선언하고 @Autowired를 지정한 생성자를 통해 의존성을 주입받는다. 그리고 인터페이스에서 정의한 메서드를 오버라이딩한다.
이제 오버라이딩된 메서드를 구현할 차례이다. 먼저 조회 메서드에 해당하는 getProduct() 메서드를 구현하겠다. getProduct() 메서드는 아래와 같이 구현할 수 있다.
@Override
public ProductResponseDto getProduct(Long number) {
Product product = productDAO.selectProduct(number);
ProductResponseDto productResponseDto = new ProductResponseDto();
productResponseDto.setNumber(product.getNumber());
productResponseDto.setName(product.getName());
productResponseDto.setPrice(product.getPrice());
productResponseDto.setStock(product.getStock());
return productResponseDto;
}현재 서비스 레이어에는 DTO 객체와 엔티티 객체가 공존하도록 설계돼 있어 변환 작업이 필요하다. DTO 객체를 생성하고 값을 넣어 초기화 작업을 수행하는데, 이런 부분은 빌더(Builder) 패털을 활용하거나 엔티티 객체나 DTO 객체 내부에 변환하는 메서드를 추가해서 간단하게 전환할 수 있다.
다음으로 ProductServiceImpl에서 저장 메서드에 해당하는 saveProduct() 메서드를 구현하겠다.
@Override
public ProductResponseDto saveProduct(ProductDto productDto) {
Product product = new Product();
product.setName(productDto.getName());
product.setPrice(productDto.getPrice());
product.setStock(productDto.getStock());
product.setCreatedAt(LocalDateTime.now());
product.setUpdatedAt(LocalDateTime.now());
Product savedProduct = productDAO.insertProduct(product);
ProductResponseDto productResponseDto = new ProductResponseDto();
productResponseDto.setNumber(savedProduct.getNumber());
productResponseDto.setName(savedProduct.getName());
productResponseDto.setPrice(savedProduct.getPrice());
productResponseDto.setStock(savedProduct.getStock());
return productResponseDto;
}저장 메서드는 로직이 간단하다. 전달받은 DTO 객체를 통해 엔티티 객체를 생성해서 초기화한 후 DAO 객체로 전달하면 된다. 다만 저장 메서드의 리턴 타입을 어떻게 지정할지는 고민해야 한다. 일반적으로 저장 메서드는 void 타입으로 작성하거나 작업의 성공 여부를 나타내는 boolean 타입으로 지정하는 경우가 많다. 리턴 타입은 해당 비즈니스 로직이 어떤 성격을 띠느냐에 따라 결정하는 것이 바람직하다.
savedProduct() 메서드는 상품 정보를 전달하고 애플리케이션을 거쳐 데이터베이스에 저장하는 역할을 수행한다. 현재 데이터를 조회하는 메서드는 데이터베이스에서 인덱스를 통해 값을 찾아야 하는데, void 로 저장 메서드를 구현할 경우에는 클라이언트가 저장한 데이터의 인덱스 값을 알 방법이 없다. 그렇기 때문에 데이터를 저장하면서 가져온 인덱스를 DTO에 담에 결괏값으로 클라이언트에 전달하는 12~16번 줄의 코드를 작성했다. 만약 이 같은 방식이 아니라 void 형식으로 메서드를 작성한다면 조회 메서드를 추가로 구현하고 클라이언트에서 한 번 더 요청해야 한다.
이번에는 업데이트 메서드를 구현한다. 업데이트 메서드에 해당하는 changeProductName() 메서드는 아래와 같이 구현할 수 있다.
@Override
public ProductResponseDto changeProductName(Long number, String name) throws Exception {
Product changedProduct = productDAO.updateProductName(number, name);
ProductResponseDto productResponseDto = new ProductResponseDto();
productResponseDto.setNumber(changedProduct.getNumber());
productResponseDto.setName(changedProduct.getName());
productResponseDto.setPrice(changedProduct.getPrice());
productResponseDto.setStock(changedProduct.getStock());
return productResponseDto;
}changeProductName() 메서드는 상품정보 중 이름을 변경하는 작업을 수행한다. 이름을 변경하기 위해 먼저 클라이언트로부터 개상을 식별할 수 있는 인덱스 값과 변경하려는 이름을 받아온다. 좀 더 견고하게 코드를 작성하기 위해서는 기존 이름도 받아와 식별자로 가져온 상품정보와 일치라는지 검증하는 단계를 추가하기도 한다.
이 기능의 핵심이 되는 비즈니스 로직은 레코드의 이름 칼럼을 변경하는 것이다. 실제 레코드 값을 변경하는 작업은 DAO에서 진행하기 때문에 서비스 레이어에서는 해당 메섣를 호출해서 결괏값만 받아온다.
마지막으로 삭제 메서드를 구현한다. 삭제 메서드에도 동일하게 검증 로직을 추가해도 되지만 우선 삭제 기능만 수행하도록 구현한다.
@Override
public void deleteProduct(Long number) throws Exception {
productDAO.deleteProduct(number);
}상품정보를 삭제하는 메서드는 리포지토리에서 제공하는 delete() 메서드를 사용할 경우 리턴받는 타입이 지정돼 있지 않기 때문에 리턴 타입을 void로 지정해 메서드를 구현한다.
컨트롤러 생성
서비스 객체의 설계를 마친 후에는 비즈니스 로직과 클라이언트의 요청을 연결하는 컨트롤러를 생성해야한다. 앞에서 컨트롤러를 생성하는 방법을 이미 다뤘으므로 여기서는 간단하게 설명하고 넘어가겠다.
컨트롤러는 클라이언트로부터 요청을 받고 해당 요청에 대해 서비스 레이어에 구현된 적절한 메서드를 호출해서 결괏값을 받는다. 이처럼 컨트롤러는 요청과 응답을 전달하는 역할만 맡는 것이 좋다.
컨트롤러는 아래와 같이 작성한다.
@RestController
@RequestMapping("/product")
public class ProductController {
private final ProductService productService;
@Autowired
public ProductController(ProductService productService){
this.productService = productService;
}
@GetMapping()
public ResponseEntity<ProductResponseDto> getProduct(Long number){
ProductResponseDto productResponseDto = productService.getProduct(number);
return ResponseEntity.status(HttpStatus.OK).body(productResponseDto);
}
@PostMapping()
public ResponseEntity<ProductResponseDto> createProduct(@RequestBody ProductDto productDto){
ProductResponseDto productResponseDto = productService.saveProduct(productDto);
return ResponseEntity.status(HttpStatus.OK).body(productResponseDto);
}
@PutMapping()
public ResponseEntity<ProductResponseDto> changeProductName(
@RequestBody ChangeProductNameDto changeProductNameDto) throws Exception {
ProductResponseDto productResponseDto = productService.changeProductName(
changeProductNameDto.getNuber(),
changeProductNameDto.getName());
return ResponseEntity.status(HttpStatus.OK).body(productResponseDto);
}
@DeleteMapping()
public ResponseEntity<String> deleteProduct(Long number) throws Exception {
productService.deleteProduct(number);
return ResponseEntity.status(HttpStatus.OK).body("정상적으로 삭제되었습니다.");
}
}ChangeProductNameDto 를 추가한다.
package com.springboot.jpa.data.dto;
public class ChangeProductNameDto {
private Long number;
private String name;
public ChangeProductNameDto(Long number, String name) {
this.number = number;
this.name = name;
}
public ChangeProductNameDto(){
}
public Long getNumber(){
return this.number;
}
public String getName() {
return this.name;
}
public void setNumber(Long number){
this.number = number;
}
public void setName(String name) {
this.name = name;
}
}반복되는 코드의 작성을 생략하는 방법 - 롬복
롬복(Lombok)은 데이터(모델) 클래스를 생성할 때 반복적으로 사용하는 getter/setter 같은 메서드를 어노테이션으로 대체하는 기능을 제공하는 라이브러리이다. 자바에서 데이터 클래스를 작성하면 대개 많은 멤버 변수를 선언하고, 각 멤버 변수별로 getter/setter 메서드를 만들어 코드가 길어지고 가독성이 낮아진다. 인텔리제이 IDEA나 이클립스 같은 IDE에서는 이러한 메서드를 자동으로 생성하는 기능을 제공하긴 하지만 가독성이 떨어진다는 점에서는 마찬가지다.
이러한 경우 롬복을 활용하면 다음과 같은 장점이 있다.
어노테이션 기반으로 코드를 자동 생성하므로 생산성이 높아진다.
반복되는 코드를 생략할 수 있어 가독성이 좋아진다.
롬복을 안다면 간단하게 코드를 유추할 수 있어 유지보수에 용이하다.
반면 몇 가지 이유로 롬복을 사용하는 것을 좋아하지 않는 개발자도 있다. 롬복을 선호하지 않는 가장 큰 이유는 코드를 어노테이션이 자동 생성하기 때문에 메서드를 개발자의 의도대로 정확하게 구현하지 못하는 경우가 발생한다는 것이다.
롬복 적용
앞에서 설명한 설치와 설정 과정을 모두 마쳤다면 정상적으로 롬복을 사용할 수 있다. 지금까지 프로젝트 실습을 진행하면서 생성한 데이터 클래스에 롬복을 적용하면서 각 어노테이션의 기능을 살펴보겠다.
먼저 Product 엔티티 클래스에 롬복을 적용해 보겠다. 아래 코드는 앞에서 살펴본 Product 엔티티 클래스이다.
package com.springboot.jpa.data.entity;
@Entity
@Table(name = "product")
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long number;
@Column(nullable = false)
private String name;
@Column(nullable = false)
private Integer price;
@Column(nullable = false)
private Integer stock;
private LocalDateTime createdAt;
private LocalDateTime updatedAt;
public Product(Long number, String name, Integer price, Integer stock, LocalDateTime createdAt,
LocalDateTime updatedAt){
this.number = number;
this.name = name;
this.price = price;
this.stock = stock;
this.createdAt = createdAt;
this.updatedAt = updatedAt;
}
public Product(){
}
... getter/setter 메서드 생략...
}참고로 위 예제에서는 코드를 조금 더 보기 편하게 getter/setter 메서드를 생략했는데, 만약 getter/setter 메서드가 모두 포함돼 있었다면 최소 100줄 이상이 될 것이다. 위 코드를 아래와 같이 어노테이션을 이용해 많은 코드를 대체할 수 있다.
package com.springboot.jpa.data.entity;
@Entity
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Table(name = "product")
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long number;
@Column(nullable = false)
private String name;
@Column(nullable = false)
private Integer price;
@Column(nullable = false)
private Integer stock;
private LocalDateTime createdAt;
private LocalDateTime updatedAt;
}이전 코드와 비교해보면 심지어 getter/setter 메서드를 생략한 예제보다 코드 라인 수가 적다. 물론 어노테이션으로 메서드를 자동 생성했기 때문에 필요한 모든 코드는 갖춰져 있다.
롬복의 주요 어노테이션
롬복은 다양한 어노테이션을 제공하고 있다. 그중 많이 사용하는 어노테이션들을 소개한다.
@Getter, @Setter
클래스에 선언돼 있는 필드에 대한 getter/setter 메서드를 생성한다.
생성자 자동 생성 어노테이션
데이터 클래스의 초기화를 위한 생성자를 자동으로 만들어주는 어노테이션은 다음의 세 가지가 있다.
- NoArgsConstructor : 매개변수가 없는 생성자를 자동 생성한다.
- AllArgsConstructor : 모든 필드를 매개변수로 갖는 생성자를 자동 생성한다.
- RequiredArgsConstructor : 필드 중 final이나 @NotNull 이 설정된 변수를 매개변수로 갖는 생성자를 자동 생성한다.
@ToString
이름 그래도 toString() 메서드를 생성하는 어노테이션이다.
@EqualsAndHashCode
@EqualsAndHashCode는객체의 동등성(Equality)와 동일성(Identity)을 비교하는 연산 메서드를 생성한다.
@Data
@Data 는 앞서 설명한 @Getter/Setter, @RequiredArgsConstructor, @ToString, @EqualsAndHashCode 를 모두 포괄하는 어노테이션이다. 즉, 앞에서 살펴본 각각의 어노테이션에서 생성하는 대부분의 코드가 필요하다면 @Data 어노테이션으로 앞에서 설명한 코드를 전부 한 번에 생성할 수 있다.
💡 롬복과 관련된 자세한 기능은 공식 사이트의 features 항목https://projectlombok.org/features/all 에서 확인할 수 있다.
해당 포스트는 장정우님,
[스프링부트 핵심가이드 : 스프링 부트를 활용한 애플리케이션 개발 실무] 를 참고하여 작성하였습니다.
리미
728x90
'23-24 > Spring 1' 카테고리의 다른 글
| [스프링 1팀] 8장 Spring Data JPA 활용 (2) | 2023.11.24 |
|---|---|
| [스프링1] 7장. 테스트 코드 작성하기 (0) | 2023.11.17 |
| [스프링 1팀] 5-6장. API를 작성하는 다양한 방법 및 데이터베이스 연동 (1) | 2023.11.03 |
| [스프링 1팀] 1장 ~ 4장. 스프링 부트란? + 개발에 앞서 알면 좋은 기초 지식 + 개발환경 구성 + 스프링부트 애플리케이션 개발하기 (0) | 2023.10.13 |
| [스프링1] 섹션6. 스프링 DB 접근 기술 JPA (0) | 2023.10.06 |