고정 헤더 영역

상세 컨텐츠
본문
728x90

10. 유효성 검사와 예외처리
10-1. 개요
애플리케이션의 비즈니스 로직이 올바르게 동작하려면 데이터를 사전 검증하는 작업이 필요하다. 이것을 유효성 검사 또는 데이터 검증이라 부른다. 유효성 검사의 예로는 여러 계층에서 들어오는 데이터에 대해 의도대로 값이 들어오는지 체크하는 과정이 있다. 이 같은 유효성 검사(validation)는 프로그래밍에서 매우 중요한 부분이며, 자바에서 가장 신경 써야 하는 것 중 하나로 NullPointException 예외가 있다.
일반적인 애플리케이션 유효성 검사의 문제점
일반적으로 사용되는 데이터 검증 로직에는 몇 가지 문제점이 있다. 계층별로 진행하는 유효성 검사는 검증 로직이 각 클래스별로 분산돼 있어 관리하기가 어렵다. 그리고 검증 로직에 의외로 중복이 많아 여러 곳에 유사한 기능의 코드가 존재할 수 있다. 마지막으로 검증해야할 값이 많다면 검증하는 코드가 길어진다. 이러한 문제로 코드가 복잡해지고 가독성이 떨어진다.
이 같은 문제를 해결하기 위해 자바 진영에서는 2009년 부터 Bean Validation이라는 데이터 유효성 검사 프레임워크를 제공한다. Bean Validation은 어노테이션을 통해 다양한 데이터를 검증하는 기능을 제공한다. Bean Validation을 사용한다는 것은 유효성 검사를 위한 로직을 DTO 같은 도메인 모델과 묶어서 각 계층에서 사용하면서 검증 자체를 도메인 모델에 얹는 방식으로 수행한다는 의미이다.
또한 Bean Validation은 어노테이션을 사용한 검증 방식이기 때문에 코드의 간결함도 유지할 수 있다.
Hibernate Validator
Hibernate Validator는 Bean Validation 명세의 구현체이다. 스프링 부트에서는 Hibernate Validator를 유효성 검사 표준으로 채택해서 사용하고 있다.
10-2. 스프링 부트에서의 유효성 검사
지금부터 애플리케이션에 유효성 검사 기능을 추가하겠습니다. 기본 프로젝트 뼈대는 7장에서 사용한 패키지와 클래스 구조를 그대로 가져와 만들겠습니다.
스프링 부트용 유효성 검사 관련 의존성 추가
원래 스프링 부트의 유효성 검사 기능은 spring-boot-starter-web에 포함돼 있었다. 하지만 스프링 부트 2.3 버전 이후로 별도의 라이브러리로 제공하고 있다. 아래와 같이 pom.xml파일에 유효성 검사 라이브러리를 의존성으로 추가하면 사용할 수 있다.
<dependencies>
...생략...
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
...생략...
</dependencies>스프링 부트의 유효성 검사
유효성 검사는 각 계층으로 데이터가 넘어오는 시점에 해당 데이터에 대한 검사를 실시한다. 스프링 부트 프로젝트에서는 계층 간 데이터 전송에 대체로 DTO 객체를 활용하고 있기 떄문에 아래 그림과 같이 유효성 검사를 DTO 객체를 대상으로 수행하는 것이 일반적이다.
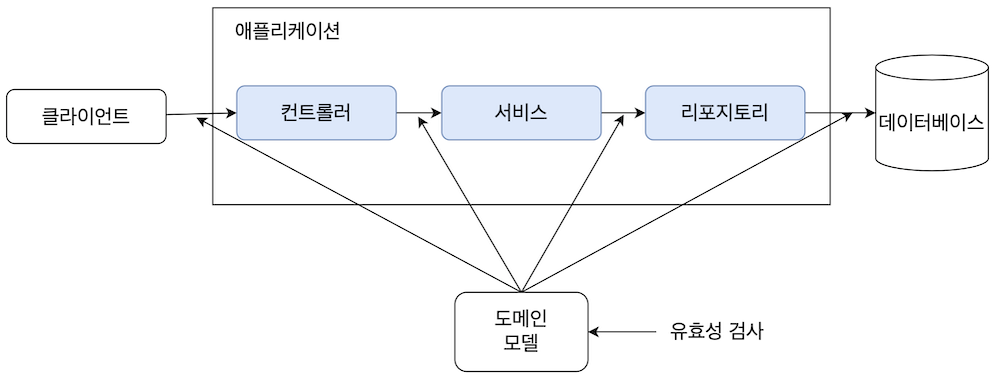
이번 장의 실습을 위한 DTO와 컨트롤러를 생성하겠다. 먼저 ValidRequestDto라는 이름의 DTO 객체를 아래와 같이 생성한다.
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
@Builder
public class ValidRequestDto {
@NotBlank
String name;
@Email
String email;
@Pattern(regexp = "01(?:0|1|[6-9])[.-]?(\\d{3}|\\d{4})[.-]?(\\d{4})$")
String phoneNumber;
@Min(value = 20) @Max(value = 40)
int age;
@Size(min = 0, max = 40)
String description;
@Positive
int count;
@AssertTrue
boolean booleanCheck;
}예제를 보면 각 필드에 어노테이션이 선언된 것을 볼 수 있다. 각 어노테이션은 유효성 검사를 위한 조건을 설정하는 데 사용된다. 대표적인 어노테이션은 다음과 같다.
문자열 검증
- @Null : null 값만 허용한다.
- @NotNull : null을 허용하지 않는다. “”, “ “는 허용한다.
- @NotEmpty : null, ““을 허용하지 않는다. “ “는 허용한다.
- @NotBlank : null, “”, “ “을 허용하지 않는다.
최댓값 / 최솟값 검증
- BigDecimal, BigInteger, int, long 등의 타입을 지원한다.
- @DemicalMax(value = "$numberString") : $numberString 보다 작은 값을 허용한다.
- @DemicalMin(value = "$numberString") : $numberString 보다 큰 값을 허용한다.
- @Min(value = $number) : $number 이상의 값을 허용한다.
- @Max(value = $number) : $number 이하의 값을 허용한다.
값의 범위 검증
- BigDecimal, BigInteger, int, long 등의 타입을 지원한다.
- @Positive : 양수를 허용한다.
- @PositiveOrZero : 0을 포함한 양수를 허용한다.
- @Nagative : 음수를 허용한다.
- @NagetiveOrZero : 0을 포함한 음수를 허용한다.
시간에 대한 검증
- Date, LocalDate, LocalDateTime등의 타입을 지원한다.
- @Future : 현재보다 미래의 날짜를 허용한다.
- @FutureOrPresent : 현재를 포함한 미래의 날짜를 허용한다.
- @Past : 현재보다 과거의 날짜를 허용한다.
- @PastOrPresent : 현재를 포함한 과거의 날짜를 허용한다.
이메일 검증
- @Email : 이메일 형식을 검사한다. ““는 허용한다.
자릿수 범위 검증
- BigDecimal, BigInteger, int, long 등의 타입을 지원한다.
- @Digits(integer = $number1, fraction = $number2) : $number1의 정수 자릿수와 $number2의 소수 자릿수를 허용한다.
Boolean 검증
- @AssertTrue : true인지 체크한다. null값은 체크하지 않는다.
- @AssertFalse : false인지 체크한다. null값은 체크하지 않는다.
문자열 길이 검증
- @Size(min = $number1, max = $number2) : $number1 이상 $number2 이하의 범위를 허용한다.
정규식 검증
- @Pattern(regexp = "$expression") : 정규식을 검사한다 정규식은 자바의 java.util.regex.Pattern 패키지의 컨벤션을 따른다.
다음으로 앞에서 생성한 DTO를 사용하는 컨트롤러 객체를 생성하겠다. 아래와 같이 ValidationController를 생성한다.
@RestController
@RequestMapping("/validation")
public class ValidationController {
private final Logger LOGGER = LoggerFactory.getLogger(ValidationController.class);
@PostMapping("/valid")
public ResponseEntity<String> checkValidationByValid(
@Valid @RequestBody ValidRequestDto validRequestDto) {
LOGGER.info(validRequestDto.toString());
return ResponseEntity.status(HttpStatus.OK).body(validRequestDto.toString());
}
}@Valid 어노테이션을 지정해야 DTO 객체에 대해 유효성 검사를 수행한다.
@Validated 활용
앞의 예제에서는 유효성 검사를 수행하기 위해 @Valid 어노테이션을 선언했다. @Valid 어노테이션은 자바에서 지원하는 어노테이션이며, 스프링도 @Validated라는 별도의 어노테이션으로 유효성 검사를 지원한다. @Valid는 @Validated 어노테이션의 기능을 포함하고 있기 때문에 @Validated로 변경할 수 있다. 또한 @Validated는 유효성 검사를 그룹으로 묶어 대상을 특정할 수 있는 기능이 있다.
검증 그룹은 별다른 내용이 없는 마커 인터페이스를 생성해서 사용한다 실습을 위해 그림과 같이 data 패키지 내에 group 패키지를 생성하고 ValidationGroup1과 ValidationGroup2라는 인터페이스를 생성한다.
public interface ValidationGroup1 {
}public interface ValidationGroup2 {
}검증 그룹 설정은 DTO 객체에서 한다. 아래와 같이 새로운 DTO 객체를 생성한다.
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
@Builder
public class ValidatedRequestDto {
@NotBlank
private String name;
@Email
private String email;
@Pattern(regexp = "01(?:0|1|[6-9])[.-]?(\\d{3}|\\d{4})[.-]?(\\d{4})$")
private String phoneNumber;
@Min(value = 20, groups = ValidationGroup1.class)
@Max(value = 40, groups = ValidationGroup1.class)
int age;
@Size(min = 0, max = 40)
private String description;
@Positive(groups = ValidationGroup2.class)
private int count;
@AssertTrue
private boolean booleanCheck;
}@Min, @Max 어노테이션이 groups 속성을 사용해 ValidationGroup1, ValidationGroup2 와 같은 그룹을 설정한다.
실제로 그룹을 어떻게 설정해서 유효성 검사를 실시할지 결정하는 것은 @Validated 어노테이션에서 한다. 유효성 검사 그룹을 설정하기 위해 컨트롤러 클래스에 아래와 같은 메서드를 추가한다.
@RestController
@RequestMapping("/validation")
public class ValidationController {
private final Logger LOGGER = LoggerFactory.getLogger(ValidationController.class);
@PostMapping("/validated")
public ResponseEntity<String> checkValidation(
@Validated @RequestBody ValidatedRequestDto validatedRequestDto){
LOGGER.info(validatedRequestDto.toString());
return ResponseEntity.status(HttpStatus.OK).body(validatedRequestDto.toString());
}
@PostMapping("/validated/group1")
public ResponseEntity<String> checkValidation1(
@Validated(ValidationGroup1.class) @RequestBody ValidatedRequestDto validatedRequestDto) {
LOGGER.info(validatedRequestDto.toString());
return ResponseEntity.status(HttpStatus.OK).body(validatedRequestDto.toString());
}
@PostMapping("/validated/group2")
public ResponseEntity<String> checkValidation2(
@Validated(ValidationGroup2.class) @RequestBody ValidatedRequestDto validatedRequestDto) {
LOGGER.info(validatedRequestDto.toString());
return ResponseEntity.status(HttpStatus.OK).body(validatedRequestDto.toString());
}
@PostMapping("/validated/all-group")
public ResponseEntity<String> checkValidation3(
@Validated({ValidationGroup1.class,
ValidationGroup2.class}) @RequestBody ValidatedRequestDto validatedRequestDto) {
LOGGER.info(validatedRequestDto.toString());
return ResponseEntity.status(HttpStatus.OK).body(validatedRequestDto.toString());
}
}
커스텀 Validation 추가
실무에서는 유효성 검사를 실시할 때 자바 또는 스프링의 유효성 검사 어노테이션에서 제공하지 않는 기능을 써야할 때도 있다. 이 경우 ConstraintValidator와 커스턴 어노테이션을 조합해서 별도의 유효성 검사 어노테이션을 생성할 수 있다. 동일한 정규식을 계속 쓰는 @Pattern 어노테이션의 경우가 가장 흔한 사례이다.
이번에는 전화번호 형식이 일치하는지 확인하는 간단한 유효성 검사 어노테이션을 생성해 보겠다. 먼저 ConstraintValidator 인터페이스를 구현하는 클래스를 생성해야 한다. 아래와 같이 TelephoneValidator클래스를 생성한다.
public class TelephoneValidator implements ConstraintValidator<Telephone,String> {
@Override
public boolean isValid(String value, ConstraintValidatorContext constraintValidatorContext) {
if(value == null){
return false;
}
return value.matches("01(?:0|1|[6-9])[.-]?(\\d{3}|\\d{4})[.-]?(\\d{4})$");
}
}TelephoneValidator 클래스를 ConstraintValidator 인터페이스의 구현체로 정의한다. 인터페이스를 선언할 때는 어떤 어노테이션 인터페이스인지 타입을 지정해야 한다.
ConstraintValidator 인터페이스에서 정의한 Telephone 인터페이스를 살펴보겠다. Telephone 인터페이스는 아래와 같이 작성할 수 있다.
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
@Constraint(validatedBy = TelephoneValidator.class)
public @interface Telephone {
String message() default " 전화번호 형식이 일치하지 않습니다.";
Class[] groups() default {};
Class[] payload() default {};
}@Target 어노테이션은 이 어노테이션을 어디서 선언할 수 있는지 정의하는데 사용된다. 예제에서는 필드에 선언할 수 있게 설정돼 있다. 그 외에 사용할 수 있는 ElementType은 다음과 같다.
- ElementType.PACKAGE
- ElementType.TYPE
- ElementType.CONSTRUCTOR
- ElementType.FIELD
- ElementType.METHOD
- ElementType.ANNOTATION_TYPE
- ElementType.LOCAL_VARIABLE
- ElementType.PARAMETER
- ElementType.TYPE_PARAMETER
- ElementType.TYPE_USE
@Retention 어노테이션은 이 어노테이션이 실제로 적용되고 유지되는 범위를 의미한다. @Retention의 적용 범위는 RetentionPolicy를 통해 지정하며, 지정 가능한 항목은 다음과 같다.
- RetentionPolicy.RUNTIME : 컴파일 이후에도 JVM에 의해 계쏙 참조한다. 리플렉션이나 로깅에 많이 사용되는 정책이다.
- RetentionPolicy.CLASS : 컴파일러가 클래스를 참조할 때까지 유지한다.
- RetentionPolicy.SOURCE : 컴파일 전까지만 유지된다. 컴파일 이후에는 사라진다.
@Constraint어노테이션을 활용해서 소개한 TelephoneValidator와 매핑하는 작업을 수행한다.
이렇게 어노테이션 인터페이스를 설정하고 나면 아래와 같이 인텔리제이 IDEA의 [Bean Validation] 탭에 앞에서 생성한 @Telephone이 추가된 것을 볼 수 있다
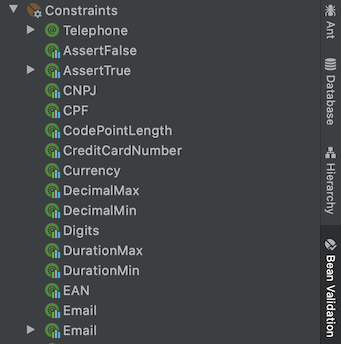
이제 직접 생성한 새로운 유효성 검사 어노테이션을 적용해 보겠다. 아래와 같이 ValidatedRequestDto 클래스에서 phoneNumber 변수의 어노테이션을 변경한다.
@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
@Builder
public class ValidatedRequestDto {
@NotBlank
private String name;
@Email
private String email;
@Telephone
private String phoneNumber;
@Min(value = 20, groups = ValidationGroup1.class)
@Max(value = 40, groups = ValidationGroup1.class)
int age;
@Size(min = 0, max = 40)
private String description;
@Positive(groups = ValidationGroup2.class)
private int count;
@AssertTrue
private boolean booleanCheck;
}@Pattern 어노테이션을 @Telephone 어노테이션으로 변경한 코드이다.
10-4. 예외 처리
애플리케이션을 개발할 때는 불가피하게 많은 오류가 발생하게 된다. 자바에서는 이러한 오류를 try/catch, throw 구문을 활용해 처리한다. 스프링 부트에서는 더욱 편리하게 예외 처리를 할 수 있는 기능을 제공한다. 이번 절에서는 예외 처리의 기초를 소개하고 스프링 부트에서 적용할 수 있는 예외 처리 방식을 알아보겠다.
예외와 에러
프로그래밍에서 예외란 입력 값의 처리가 불가능하거나 참조된 값이 잘못도니 경우 등 애플리케이셔닝 정상적으로 동작하지 못하는 상황을 의미한다. 예외는 개발자 직접 처리할 수 있는 것이므로 미리 코드 설계를 통해 처리할 수 있다.
다음으로 에러가 있다. 많은 사람들이 예외와 비슷한 의미로 사용하고 있지만 소프트웨어 공학에서는 다르게 사용되는 언어이다. 에러는 주로 자바의 가상머신에서 발생시키는 것으로 예외와 달리 애플리케이션 코드에서 처리할 수 있는 것이 거의 없다. 대표적인 예로 메모리 부족, 스택 오버플로 등이 있다. 이러한 에러는 발생 시점에서 처리하는 것이 아니라 미리 애플리케이션의 코드를 살펴보면서 문제가 발생하지 않도록 예방해서 원천적으로 차단해야 한다.
예외 클래스
자바의 예외 클래스는 아래와 같은 상속 구조를 갖추고 있다.
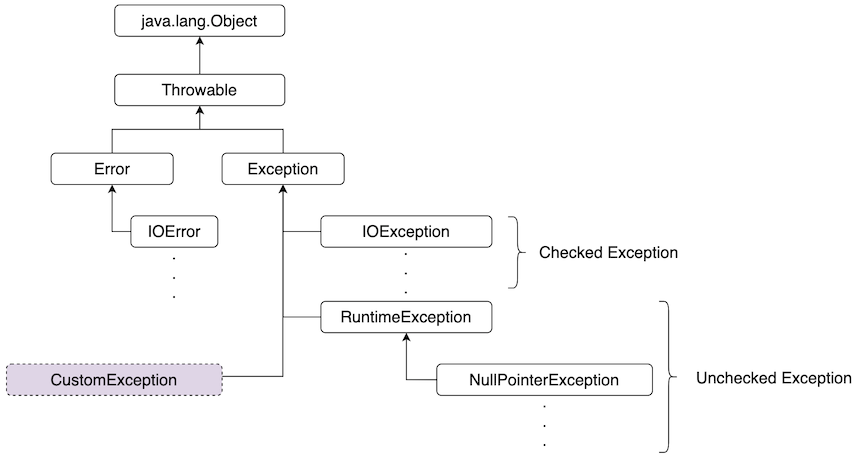
모든 예외 클래스는 Throwable 클래스를 상속받는다. 그리고 가장 익숙하게 볼 수 있는 Exception 클래스는 다양한 자식 클래스를 가지고 있다. 이 클래스는 크게 Checked Exception과 Unchecked Exception으로 구분할 수 있다.
Checked Exception은 컴파일 단계에서 확인 가능한 예외 상황이다. 이러한 예외는 IDE에서 캐치해서 반드시 예외 처리를 할 수 있도록 표시헤준다. 반면 Unchecked Exception은 런타임 단계에서 확인되는 예외 상황을 나타낸다. 즉, 문법상 문제는 없지만 프로그램이 동작하는 도중 예기치 않은 상황이 생겨 발생하는 예외를 의미한다.
예외 처리 방법
예외가 발생했을 때 이를 처리하는 방법은 크게 세 가지가 있다.
- 예외 복구
- 예외 처리 회피
- 예외 전환
먼저 예외 복구 방법은 예외 상황을 파악해서 문제를 해결하는 방식이다. 대표적인 방법이 try/catch 구문이다. try 블록에는 예외가 발생할 수 있는 코드를 작성한다. 대체로 외부 라이브러리를 사용하는 경우에는 try 블록을 사용하라는 IDE의 알람이 발생하지만 개발자가 직접 작성한 로직은 예외 상황을 예측해서 try 블록에 포함시켜야 한다. 그리고 catch 블록을 통해 try 블록에서 발생하는 예외 상황을 처리하는 내용을 작성한다. 이때 catch 블록은 여러 개를 작성할 수 있다. 이 경우 예외 상황이 발생하면 애플리케이션에서는 여러 개의 catch 블록을 순차적으로 거치면서 예외 유형과 매칭되는 블록을 찾아 예외 처리 동작을 수행한다.
int a = 1;
String b = "a";
try {
System.out.println(a + Integer.parseInt(b));
} catch (NumberFormatException e) {
b = "2";
System.out.println(a + Integer.parseInt(b));
}또 다른 예외 처리 방법 중 하나는 예외 처리를 회피하는 방법이다. 이방법은 예외가 발생한 시점에서 바로 처리하는 것이 아니라 예외가 발생한 메서드를 호출한 곳에서 에러 처리를 할 수 있게 전가하는 방식이다. 이때 throw 키워드를 사용해 어떤 예외가 발생했는지 호출부에 내용을 전달할 수 있다.
int a = 1;
String b = "a";
try {
System.out.println(a + Integer.parseInt(b));
} catch (NumberFormatException e) {
throw new NumberFormatException("숫자가 아닙니다.");
}마지막으로 예외 전환 방법이 있다. 이 방법은 앞의 두 방식을 적절하게 섞은 방식이다. 예외가 발생했을 때 어떤 예외가 발생했느냐에 따라 호출부로 예외 내용을 전달하면서 좀 더 적합한 예외 타입을 전달할 필요가 있다. 또는 애플리케이션에서 예외 처리를 좀 더 단순하게 하기 위해 래핑(wrapping)헤야 하는 경우도 있다. 이런 경우에는 try/catch 방식을 사용하면서 catch블록에서 throw 키워드를 사용해 다른 예외 타입으로 전달하면 된다. 이 방식은 앞으로 나올 커스텀 예외를 만드는 과정에서 사용되는 방법이므로 별도로 예제를 보여주지 않겠다.
스프링 부트의 예외 처리 방식
웹 서비스 애플리케이션에서는 외부에서 들어오는 요청에 담신 데이터를 처리하는 경우가 많다. 그 과정에서 예외가 발생하면 예외를 복구해서 정상으로 처리하기보다는 요청을 보낸 클라이언트에 어떤 문제가 발생했는지 상황을 전달하는 경우가 많다. 이번 절에서는 이를 반영해서 예외 상황을 복구하는 방법보다는 스프링 부트에서 사용하는 예외 처리 방법을 중심으로 설명하고 실습하겠다.
예외가 발생했을 떄 클라이언트에 오류 메시지를 전달하려면 각 레이어에서 발생한 예외를 엔드포인트 레벨인 컨트롤러로 전달해야 한다. 이렇게 전달받은 예외를 스프링 부트에서 처리하는 방식으로 크게 두 가지가 있다.
- @(Rest)ControllerAdvice와 @ExceptionHandler를 통해 모든 컨트롤러의 예외를 처리
- @ExceptionHandler를 통해 특정 컨트롤러의 예외를 처리
먼저 @RestControllerAdvice를 활용한 핸들러 클래스를 생성하겠다. 아래와 같이 CustomExceptionHandler클래스를 생성한다.
@RestControllerAdvice
public class CustomExceptionHandler {
private final Logger LOGGER = LoggerFactory.getLogger(CustomExceptionHandler.class);
@ExceptionHandler(value = RuntimeException.class)
public ResponseEntity<Map<String, String>> handlerException(RuntimeException e, HttpServletRequest request){
HttpHeaders responseHeaders = new HttpHeaders();
HttpStatus httpStatus = HttpStatus.BAD_REQUEST;
LOGGER.error("Advice 내 HandleException 호출, {}, {}", request.getRequestURI(), e.getMessage());
Map<String, String> map = new HashMap<>();
map.put("error type", httpStatus.getReasonPhrase());
map.put("code", "400");
map.put("message", e.getMessage());
return new ResponseEntity<>(map, responseHeaders, httpStatus);
}
}예제에서 사용한 @RestcontrollerAdvice와 이 예제에서는 사용하지 않는 @ControllerAdvice는 스프링에서 제공하는 어노테이션이다. 이 어노테이션은 @Controller나 @RestController 에 발생하는 예외를 한 곳에서 관리하고 처리할 수 있게 하는 기능을 수행한다. 즉, 다음과 같이 별도 설정을 통해 예외를 관제하는 범위를 지정할 수 있다.
@RestControllerAdvice(basePackages = "com.springboot.valid_exception")이 예제를 테스트하기 위해 발생시킬 수 있는 컨트롤러를 생성하겠다. 아래와 같이 ExceptionController를 생성한다.
@RestController
@RequestMapping("/exception")
public class ExceptionController {
@GetMapping
public void getRuntimeException(){
throw new RuntimeException("getRuntimeException 메서드 호출");
}
}컨트롤러에서 던진 예외는 @ControllerAdvice또는 @RestControllerAdvice가 선언돼 있는 핸들러 클래스에서 매핑된 예외 타입을 찾아 처리하게 된다. 두 어노테이션은 별도 범위 설정이 없으면 전역 범위에서 예외를 처리하기 때문에 특정 컨트롤러에서만 동작하는 @ExceptionHandler 메서드를 생성해서 처리할 수도 있다. ExceptionController에 아래와 같이 메서드를 추가로 생성해 보자.
@RestController
@RequestMapping("/exception")
public class ExceptionController {
private final Logger LOGGER = LoggerFactory.getLogger(ExceptionController.class);
@GetMapping
public void getRuntimeException(){
throw new RuntimeException("getRuntimeException 메서드 호출");
}
@ExceptionHandler(value = RuntimeException.class)
public ResponseEntity<Map<String, String>> handleException(RuntimeException e, HttpServletRequest request) {
HttpHeaders responseHeaders = new HttpHeaders();
responseHeaders.setContentType(MediaType.APPLICATION_JSON);
HttpStatus httpStatus = HttpStatus.BAD_REQUEST;
LOGGER.error("클래스 내 handleException 호출, {}, {}", request.getRequestURI(),
e.getMessage());
Map<String, String> map = new HashMap<>();
map.put("error type", httpStatus.getReasonPhrase());
map.put("code", "400");
map.put("message", e.getMessage());
return new ResponseEntity<>(map, responseHeaders, httpStatus);
}
}예제처럼 컨트롤러 클래스 내에 @ExceptionHandler 어노테이션을 사용한 메서드를 선언하면 해당 클래스에 국한해서 예외를 처리할 수 있다.
만약 @ControllerAdvice와 컨트롤러 내에 동일한 예외 타입을 처리한다면 좀 더 우선수위가 높은 클래스 내의 핸들러 메서드가 사용되는 것을 볼 수 있다.
우선순위를 비교하는 방법은 총 두 가지가 있다.
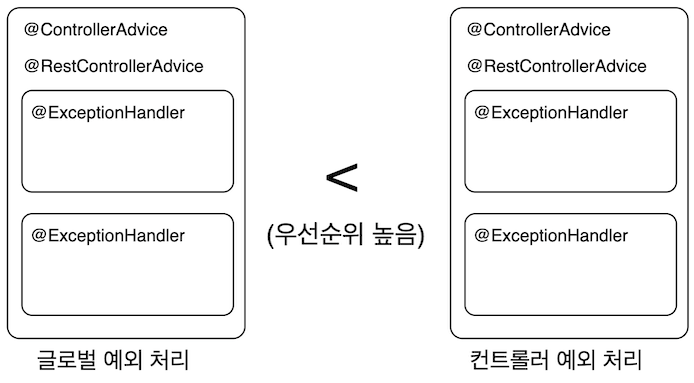
위 그림 처럼 @ControllerAdvice의 글로벌 예외 처리와 @Controller 내의 컨트롤러 예외 처리에 동일한 타입의 예외 처리를 하게 되면 범위가 좁은 컨트롤러의 핸들러 메서드가 우선순위를 갖게 된다.
커스텀 예외
애플리케이션을 개발하다 보면 점점 예외로 처리할 영역이 늘어나고, 예외 상황이 다양해지면서 사용하는 예외 타입도 많아진다. 대부분의 상황에서는 자바에서 이미 적절한 상황에 사용할 수 있도록 제공하는 표준 예외(Standard Exception)를 사용하면 해경된다. 사실 애플리케이션의 예외 처리에는 표준 예외만 사용해도 모든 상황들을 처리할 수 있다. 그런데 왜 커스텀 예외(Custom Exception)를 만들어 사용해야할까?
커스텀 예외를 만들어서 사용하면 네이밍에 개발자의 의도를 담을 수 있기 때문에 이름만으로도 어느 정도 예외 상황을 짐작할 수 있다. 앞에서 언급했듯이 표준 예외에서도 다양한 예외 상황을 처리할 수 있는 클래스를 제공하고 있지만 표준 예외에서 제공하는 클래스는 해당 예외 타입의 이름만으로 이해하기 어려운 경우가 있다. 그래서 표준 예외를 사용할 때는 예외 메시지를 상세히 작성해야 하는 번거로움이 있다.
또한 커스텀 예외를 사용하면 애플리케이션에서 발생하는 예외를 개발자가 직접 관리하기가 수월해진다. 표준 예외를 상속받은 커스텀 예외들을 개발자가 직접 코드로 관리하기 때문에 책임 소재를 애플리케이션 내부로 가져올 수 있게 된다. 이를 통해 동일한 예외 상황이 발생할 경우 한 곳에서 처리하며 특정 상황에 맞는 예외 코드를 적용할 수 있게 된다.
마지막으로 커스텀 예외를 사용하면 예외 상황에 대한 처리도 용이하다. 앞에서 @ControllerAdvice와 @ExceptionHandler에 대해 알아봤는데, 이러한 어노테이션을 사용해 애플리케이션에서 발생하는 예외 상황들을 한 곳에서 처리할 수 있었다. 예를 들어, RuntimeException에 대해 @ControllerAdvice의 내부에서 표준 예외 처리를 하는 로직을 작성한 경우 개발자가 의도한 RuntimeException에 대해 @ControllerAdvice의 내부에서 표준 예외 처리를 하는 로직을 작성한 경우 개발자가 의도한 RuntimeException부분이 아닌 의도하지 않은 부분에서 발생하는 에러들이 존재할 수 있다. 표준 예외를 사용하면 이처럼 의도하지 않은 예외 상황도 정해진 예외 처리 코드에서 처리하기 때문에 어디에서 문제가 발생했는지 확인하기가 어렵다. 그러나 커스텀 예외로 관리하면 의도하지 않았던 부분에서 발생한 예외는 개발자가 관리하는 예외 처리 코드가 처리하지 않으므로 개발 과정에서 혼동할 여지가 줄어든다.
커스텀 예외 클래스 생성하기
이제 커스텀 예외를 생성하고 활용하는 방법을 살펴보겠다. 커스텀 예외는 만드는 목적에 따라 생성하는 방법이 다르다. 이 책에서는 스프링 환경에서 사용할 수 있는 @ControllerAcvice와 @ExceptionHandler의 무분별한 예외 처리를 방지하기 위한 커스텀 예외를 생성하는 과정을 실흡해 보겠다. 우선 앞에서 한번 살펴본 그림을 다시 보자.
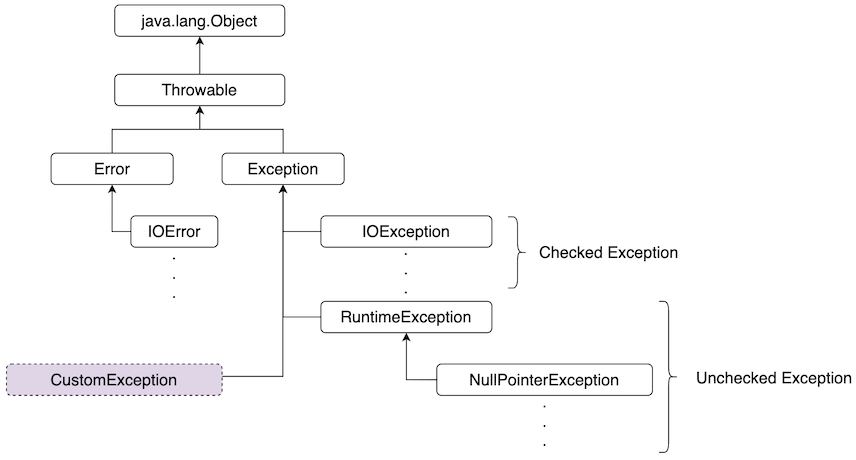
커스텀 예외는 예외가 발생하는 상황에 해당하는 상위 예외 클래스를 상속받는다. 그래서 커스텀 예외는 상위 예외 클래스보다 좀 더 구체적인 이름을 사용하기도 한다. 그러나 여기서는 커스텀 예외의 네이밍보다는 클래스의 구조적인 설계를 통한 예외 클래스 생성 방법을 알아보겠다.
먼저 Exception클래스의 커스텀 예외를 만들어보겠다. 예외 클래스의 상속 구조는 보면 Exception클래스는 Throwable 클래스를 상속받는다. 아래 실습에서는 그중 필수적으로 사용되는 message 변수를 이용해 Exception 클래스의 커스텀 예외를 만들겠다. 먼저 Exception 클래스는 아래와 같다.
public class Exception extends Throwable {
static final long serialVersionUID = -3387516993124229948L;
public Exception() {
super();
}
public Exception(String message) {
super(message);
}
public Exception(String message, Throwable cause) {
super(message, cause);
}
public Exception(Throwable cause) {
super(cause);
}
protected Exception(String message, Throwable cause,
boolean enableSuppression,
boolean writableStackTrace) {
super(message, cause, enableSuppression, writableStackTrace);
}
}생성자는 String 타입의 메시지 문자열을 받고 있다. 이 생성자는 Throwable 클래스의 생성자를 호출한다.
public class Throwable implements Serializable {
private static final long serialVersionUID = -3042686055658047285L;
private transient Object backtrace;
private String detailMessage;
... 생략 ...
public Throwable() {
fillInStackTrace();
}
public Throwable(String message) {
fillInStackTrace();
detailMessage = message;
}
public String getMessage() {
return detailMessage;
}
public String getLocalizedMessage() {
return getMessage();
}
... 생략 ...
}위에서 살펴볼 수 있듯이 Exception 클래스는 부모 클래스인 Throwable 클래스의 15~18번 줄의 생성자를 호출하게 되며, message 변수의 값을 detailMessage 변수로 전달받는다. 커스텀 예외를 생성하는 경우에도 이 message 변수를 사용하게 된다.
그리고 HttpStatus를 커스텀 예외 클래스에 포함시키면 핸들러 안에서 선언해서 사용하는 것이 아닌 예외 클래스만 전달받으면 그 안에 내용이 포함돼 있는 구조로 설계할 수 있다. 참고로 HttpStatus는 열거형(Enum)이다. 열거형은 서로 관련 있는 상수를 모든 심볼릭한 명칭의 집합이다. 쉽게 생각해서 클래스 타입의 상수로 볼 수 있다. 아래에서 HttpStatus의 주요 코드 일부를 살펴보겠다.
public enum HttpStatus {
// --- 4xx Client Error ---
BAD_REQUEST(400, HttpStatus.Series.CLIENT_ERROR, "Bad Request"),
UNAUTHORIZED(401, HttpStatus.Series.CLIENT_ERROR, "Unauthorized"),
PAYMENT_REQUIRED(402, HttpStatus.Series.CLIENT_ERROR, "Payment Required"),
FORBIDDEN(403, HttpStatus.Series.CLIENT_ERROR, "Forbidden"),
NOT_FOUND(404, HttpStatus.Series.CLIENT_ERROR, "Not Found"),
METHOD_NOT_ALLOWED(405, HttpStatus.Series.CLIENT_ERROR, "Method Not Allowed"),
private HttpStatus(int value, HttpStatus.Series series, String reasonPhrase) {
this.value = value;
this.series = series;
this.reasonPhrase = reasonPhrase;
}
public int value() {
return this.value;
}
public HttpStatus.Series series() {
return this.series;
}
}HttpStatus는 value, series, reasonPhrase 변수로 구성된 객체를 제공한다. 흔히 볼 수 있는 Http응답 코드와 메시지이다. 위 예제에서는 4xx 코드만 나왔지만 1xx, 2xx, 3xx, 4xx, 5xx에 대해서도 코드 모음이 구성돼 있다.
최종적으로 이번에 만들어볼 커스텀 예외 클래스를 생성하는 데 필요한 내용은 다음과 같이 정리할 수 있다.
- 에러 타입(error type) : HttpStatus의 reasonPharse
- 에러 코드(error code) : HttpStatus의 value
- 메시지(message) : 상황별 상세 메시지
위와 같은 구성으로 커스텀 예외 클래스를 생성하겠다. 추가로 애플리케이션에서 가지고 있는 도메인 레벨을 메시지에 표현하기 위해 ExceptionClass 열거형 타입을 생성하겠다. 이를 도식화하면 아래 그림과 같은 커스텀 예외 클래스 구조가된다.
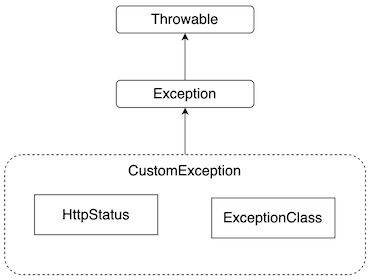
커스텀 예외 클래스를 생성하기에 앞서 도메인 레벨 표현을 위한 열거형을 아래와 같이 생성하겠다.
public class Constants {
public enum ExceptionClass {
PRODUCT("Product");
private String exceptionClass;
ExceptionClass(String exceptionClass) {
this.exceptionClass = exceptionClass;
}
public String getExceptionClass() {
return exceptionClass;
}
@Override
public String toString() {
return getExceptionClass() + " Exception. ";
}
}
}예제에서는 Constants라는 클래스를 생성한 후 ExceptionClass를 내부에 생성했다. 열거형을 별도로 생성해도 무관하지만 상수 개념으로 사용하기 때문에 앞으로의 확장성을 위해 Constants라는 상수들을 통합 관리하는 클래스를 생성하고 내부에 ExceptionClass를 선언했다.
public class CustomException extends Exception {
private Constants.ExceptionClass exceptionClass;
private HttpStatus httpStatus;
public CustomException(Constants.ExceptionClass exceptionClass, HttpStatus httpStatus, String message) {
super(exceptionClass.toString() + message);
this.exceptionClass = exceptionClass;
this.httpStatus = httpStatus;
}
public Constants.ExceptionClass getExceptionClass() {
return exceptionClass;
}
public int getHttpStatusCode() {
return httpStatus.value();
}
public String getHttpStatusType() {
return httpStatus.getReasonPhrase();
}
public HttpStatus getHttpStatus() {
return httpStatus;
}
}위의 커스텀 예외 클래스는 앞에서 만든 ExceptionClass와 HttpStatus를 필드로 가진다. 두 객체를 기반으로 예외 내용을 정의한다.
11. 액츄에이터
11-1. 프로젝트 생성
애플리케이션을 개발하는 단계를 지나 운영 단계에 접어들면 애플리케이션이 정상적으로 동작하는지 모니터링하는 환경을 구축하는 것이 매우 중요해진다. 스프링 부트 액추에이터는 HTTP 엔드포인트나 JMX를 활용해 애플리케이션을 모니터링하고 관리할 수 있는 기능을 제공한다. 이번 장에서는 액추에이터의 환경을 설정하고 활용하는 방법을 다룰 예정이다.
💡 JMX?
JMX(Java Management Extensions)는 실행 중인 애플리케이션의 상태를 모니터링하고 설정을 변경할 수 있게 해주는 APP이다.
프로젝트 생성 및 액츄에이터 종속성 추가
이번 장에서 사용할 새로운 프로젝트를 생성하겠다. 스프링 부트 버전은 이전과 같은 2.5.6 버전으로 진행하며, 다음과 같은 내용을 설정한다.
groupId : com.springboot
artifactId : actuator
name : actuator
Developer Tools : Spring Configuration Processor
Web : Spring Web
그리고 이전 장에서 사용한 SwaggerConfiguration 클래스를 가져오고 그에 따른 의존성을 추가한다.
액추에이터 기능을 사용하려면 애플리케이션에 spring-boot-starter-actuator 모듈의 종속성을 추가해야 한다. 아래와 같이 pom.xml파일에 추가하면 된다.
<dependencies>
... 생략 ...
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
... 생략 ...
</dependencies>11-2. 엔드포인트
액추에이터의 엔드포인트는 애플리케이션의 모니터링을 사용하는 경로이다. 스프링 부트에는 여러 내장 엔드포인트가 포함돼 있으며, 커스텀 엔드포인트를 추가할 수도 있다. 액푸에이터를 추가하면 기본적으로 엔드포인트 URL로 /actuator가 추가되며 이 뒤에 경로를 추가해 상세 내역에 접근한다. 만약 /actuator 경로가 아닌 다른 경로를 사용하고 싶다면 아래와 같이 application.properties파일에 작성한다.
management.endpoints.web.base-path=/custom-path엔드포인트 활성화 여부와 노출 여부를 설정할 수 있다. 활성화는 기능 자체를 활성화할 것인지를 결정하는 것으로, 비활성화된 엔트포인트는 애플리케이션 컨텍스트에서 완전히 제거된다. 엔트포인트를 활성화하려면 application.propertis 파일에 속성을 추가하면 된다. 간단한 예로 아래와 같이 작성할 수 있다.
management.endpoint.shutdown.enabled=true
management.endpoint.caches.enabled=true위 예제의 설정은 엔드포인트의 shutdown기능은 활성화하고 caches 기능은 비활성화하겠다는 의미이다.
또한 액추에이터 설정을 통해 기능 활성화/비활성화가 아니라 엔드포인트의 노출 여부만 설정하는 것도 가능하다. 노출 여부는 JMX를 통한 노출과 HTTP를 통한 노출이 있어 아래와 같이 설정이 구분된다.
## 엔드포인트 노출 설정
## HTTP 설정
management.endpoints.web.exposure.include=*
management.endpoints.web.exposure.exclude=threaddump, heapdump
## JMX 설정
management.endpoints.jmx.exposure.include=*
management.endpoints.jmx.exposure.exclude=threaddump, heapdump위 설정을 해석하면 web과 jmx 환경에서 엔드포인트를 전체적으로 노출하며, 스레드 덤프(thread dump)와 힙 덤프(heap dump) 기능은 제외하겠다는 의미이다.
11-3. 액추에이터 기능 살펴보기
액추에이터를 활성화하고 노출 지점도 설정하고 나면 애플리케이션에서 해당 기능을 사용할 수 있다. 모든 기능을 살펴보기 위해서는 다른 의존성을 추가하거나 몇 가지 설정을 추가해야 하기 때문에 이번 절에서는 기능 추가 없이 액추에이터 설정만으로 볼 수 있는 기능 위주로 살펴보겠다.
애플리케이션 기본 정보(/info)
액추에이터의 /info 엔드포인트를 활용하면 가동 중인 애플리케이션의 정보를 볼 수 있다. 제공하는 정보의 범위는 애플리케이션에서 몇 가지 방법을 거쳐 제공할 수 있으나 application.properties파일에 ‘info.’ 로 시작하는 속성 값들을 정의하는 것이 가장 쉬운 방법이다. 간단한 예로 아래와 같이 애플리케이션의 정보를 작성할 수 있다.
info.organization.name=wikibooks
info.contact.email=thinkground.flature@email.com
info.contact.phoneNumber=010-1234-5678그러고 나서 애플리케이션을 가동한 후 브라우저에서 아래 URL에 접근하면 아래와 같은 결괏값이 확인된다.
http://localhost:8080/actuator/info
{
"organization":{
"name":"wikibooks"
},
"contact":{
"email":"thinkground.flature@email.com",
"phoneNumber":"010-1234-5678"
}
}참고로 출력 결과가 한 줄로 나와 보기 힘들 경우에는 JSON Formatter 사이트(https://jsonformatter.curiousconcept.com/)를 통해 출력 결과를 좀 더 보기 쉽게 확인할 수 있다.
애플리케이션 상태(/health)
/health 엔드포인트를 활용하면 애플리케이션의 상태를 확인할 수 있다. 별도의 설정 없이 다음 URL에 접근하면 아래와 같은 결과를 확인할 수 있다.
http://localhost:8080/actuator/health
{"status":"UP"}이 결과는 주로 네트워크 계층 중 L4(Loadbalancing) 레벨에서 애플리케이션의 상태를 확인하기 위해 사용된다. 상세 상태를 확인하고 싶다면 아래와 같이 설정하면 된다.
management.endpoint.health.show-details=always빈 정보 확인(/beans)
액추애이터의 /beans 엔드포인트를 사용하면 스프링 컨테이너에 등록된 스프링 빈의 전체 목록을 표시할 수 있다. 이 엔드포인트는 JSON 형식으로 빈의 정보를 반환한다. 다만 스프링은 워낙 많은 빈이 자동으로 등록되어 운영되기 때문에 실제로 내용을 출력해서 육안으로 내용을 파악하기는 어렵다. 간단하게 출력된 내용을 보면 아래와 같다.
http://localhost:8080/actuator/beans
{
"contexts":{
"application":{
"beans":{
"endpointCachingOperationInvokerAdvisor":{
"aliases":[],
"scope":"singleton",
"type":"org.springframework.boot.actuate.endpoint.invoker.cache.CachingOperationInvokerAdvisor", ...
},
"parentId":null
}
}
}스프링 부트의 자동설정 내역 확인(/conditions)
스프링 부트의 자동설정(AutoConfiguration) 조건 내역을 확인하려면 ‘/conditions’ 엔드포인트를 사용한다. 다음 URL로 접근하면 아래와 같은 내용을 확인할 수 있다.
http://localhost:8080/actuator/conditions
{
"contexts":{
"application":{
"positiveMatches":{
"AuditEventsEndpointAutoConfiguration":[
{
"condition":"OnAvailableEndpointCondition",
"message":"@ConditionalOnAvailableEndpoint no property management.endpoint.auditevents.enabled found so using endpoint default; @ConditionalOnAvailableEndpoint marked as exposed by a 'management.endpoints.jmx.exposure' property"
}
],
"BeansEndpointAutoConfiguration":[
{
"condition":"OnAvailableEndpointCondition",
"message":"@ConditionalOnAvailableEndpoint no property management.endpoint.beans.enabled found so using endpoint default; @ConditionalOnAvailableEndpoint marked as exposed by a 'management.endpoints.jmx.exposure' property"
}
],
"BeansEndpointAutoConfiguration#beansEndpoint":[
{
"condition":"OnBeanCondition",
"message":"@ConditionalOnMissingBean (types: org.springframework.boot.actuate.beans.BeansEndpoint; SearchStrategy: all) did not find any beans"
}
],...
}
}
}
}출력 내용은 크게 positiveMatches 와 negativeMatches 속성으로 구분되는데, 자동설정의 @Conditional에 따라 평가된 내용을 표시한다.
스프링 환경변수 정보(/env)
/env 엔드포인트는 스프링의 환경변수 정보를 확인하는 데 사용된다. 기본적으로 application.properties 파일의 변수들이 표시되며, OS, JVM의 환경변수도 함께 표시된다. 다음 URL로 접근하면 아래와 같은 결과를 확인할 수 있다. 참고로 /env 엔드포인트의 출력값은 내용이 매우 복잡하기 때문에 일부 내용만 발췌했다.
http://localhost:8080/actuator/env
{
"activeProfiles":[
],
"propertySources":[
{
"name":"server.ports",
"properties":{
"local.server.port":{
"value":8080
}
}
},
{
"name":"servletContextInitParams",
"properties":{
}
},
{
"name":"systemProperties",
"properties":{
"sun.desktop":{
"value":"windows"
},
"awt.toolkit":{
"value":"sun.awt.windows.WToolkit"
},
"java.specification.version":{
"value":"11"
},
"sun.cpu.isalist":{
"value":"amd64"
},
"sun.jnu.encoding":{
"value":"MS949"
},
...
}
}
}
}만약 일부 내용에 포함된 민감한 정보를 가리기 위해서는 management.endpoint.env.keys-to-sanitize 속성을 사용하면 된다. 해당 속성에 넣을 수 있는 값은 단순 문자열이나 정규식을 활용한다.
로깅 레벨 확인(/loggers)
애플리케이션의 로깅 레벨 수준이 어떻게 설정돼 있는지 확인하려면 /loggers 엔드포인트를 사용할 수 있다. 다음 URL에 접근하면 아래와 같은 결과가 출력된다. 참고로 출력 결과가 매우 길기 때문에 일부 내용만 발췌했다.
http://localhost:8080/actuator/loggers
{
"levels":[
"OFF",
"ERROR",
"WARN",
"INFO",
"DEBUG",
"TRACE"
],
"loggers":{
"ROOT":{
"configuredLevel":"INFO",
"effectiveLevel":"INFO"
},
"_org":{
"configuredLevel":null,
"effectiveLevel":"INFO"
},
"_org.springframework":{
"configuredLevel":null,
"effectiveLevel":"INFO"
},
"_org.springframework.web":{
"configuredLevel":null,
"effectiveLevel":"INFO"
},
"_org.springframework.web.servlet":{
"configuredLevel":null,
"effectiveLevel":"INFO"
},
"groups":{
"web":{
"configuredLevel":null,
"members":[
"org.springframework.core.codec",
"org.springframework.http",
"org.springframework.web",
"org.springframework.boot.actuate.endpoint.web",
"org.springframework.boot.web.servlet.ServletContextInitializerBeans"
]
},
"sql":{
"configuredLevel":null,
"members":[
"org.springframework.jdbc.core",
"org.hibernate.SQL",
"org.jooq.tools.LoggerListener"
]
}
}
}위 예제는 GET 메서드로 호출한 결과이며, POST 형식으로 호출하면 로깅 레벨을 변경하는 것도 가능하다.
11-4. 액추에이터 커스텀 기능 만들기
앞에서 살펴봤듯이 액추에이터는 다양한 정보를 가공해서 제공한다. 그 밖에 개발자의 요구사항에 맞춘 커스텀 기능 설정도 제공한다. 커스텀 기능을 개발하는 방식에는 크게 두 가지가 있다. 첫 번째는 기존 기능에 내용을 추가하는 방식이고, 두 번째는 새로운 엔드포인트를 개발하는 방식이다.
정보 제공 인터페이스의 구현체 생성
액추에이터를 커스터마이징하는 가장 간단한 방법은 앞에서 /info 엔드포인트의 내용을 추가한 것처럼 application.properties 파일 내에 내용을 추가하는 것이다. 그러나 이 방법은 많은 내용을 담을 때는 관리 측면이 좋지 않다.
그래서 커스텀 기능을 설정할 때는 별도의 구현체 클래스를 작성해서 내용을 추가하는 방법을 많이 활용된다. 액추에이터에서는 InfoContributor 인터페이스를 제공하고 있는데, 이 인터페이스를 구현하는 클래스를 생성하면 된다. 아래와 같이 InfoContributor 인터페이스에 대한 구현 클래스를 생성한다.
@Component
public class CustomInfoContributor implements InfoContributor {
@Override
public void contribute(Info.Builder builder) {
Map<String, Object> content = new HashMap<>();
content.put("code-info", "InfoContributor 구현체에서 정의한 정보입니다.");
builder.withDetail("custom-info-contributor", content);
}
}새로 생성한 클래스를 InfoContributor 인터페이스의 구현체로 설정하면 contributor 메서드를 오버라이딩할 수 있게 된다. 이 메서드에서 파라미터로 받은 Builder객체는 액추에이터 패키지의 Info클래스 안에 정의돼 있는 클래스로서 info 엔드포인트에서 보여줄 내용을 담는 역할을 수행한다. 이렇게 객체를 가져와 6~8번 줄처럼 콘텐츠를 담아 builder에 포함하면 엔드포인트 출력 결과에서 확인할 수 있다. 아래와 같이 설정한 후 애플리케이션을 재가동해서 엔드포인트를 호출하면 아래와 같은 결과를 볼 수 있다.
{
"organization":{
"name":"wikibooks"
},
"contact":{
"email":"thinkground.flature@email.com",
"phoneNumber":"010-1234-5678"
},
"custom-info-contributor":{
"code-info":"InfoContributor 구현체에서 정의한 정보입니다."
}
}보다시피 기존 application.properties 에서 정의했던 속성값을 비롯해 구현체 클래스에서 포함한 내용이 추가된 것을 볼 수 있다.
커스텀 엔드포인트 생성
@EndPoint 어노테이션으로 빈에 추가된 객체들은 @ReadOperation, @WriteOperation, @DeleteOperation 어노테이션을 사용해 JMX나 HTTP를 통해 커스텀 엔드포인트를 노출시킬 수 있다. 만약 JMX에서만 사용하거나 HTTP에서만 사용하는 것을 제한하고 싶다면 @JmxEndpoint, @WebEndpoint 어노테이션을 사용하면 된다.
이 책에서는 간단하게 애플리케이션에 메모 기록을 남길 수 있는 기능을 엔드포인트로 생성하겠다. 아래와 같이 엔드포인트 클래스를 생성한다.
@Component
@Endpoint(id = "note")
public class NoteEndpoint {
private Map<String, Object> noteContent = new HashMap<>();
@ReadOperation
public Map<String, Object> getNote(){
return noteContent;
}
@WriteOperation
public Map<String, Object> writeNote(String key, Object value){
noteContent.put(key, value);
return noteContent;
}
@DeleteOperation
public Map<String, Object> deleteNote(String key){
noteContent.remove(key);
return noteContent;
}
}위 코드에서 @Endpoint 어노테이션을 사용하고 있다. 이 어노테이션을 선언하면 액추에이터에 엔드포인트로 자동으로 등록되며 id 속성값으로 경로를 정의할 수 있다. 또한 enableByDefault라는 속성으로 현재 생성하는 엔드포인트의 기본 활성화 여부도 설정 가능한다. enableByDefault 속성의 기본값은 true로서 값을 별도로 설정하지 않으면 활성화된다.
엔드포인트를 설정하는 클래스에는 @ReadOpertation, @WriteOperation, @DeleteOperation 어노테이션을 사용해 각 동작 메서드를 생성할 수 있다.
@ReadOperation 어노테이션을 정의해 HTTP, GET 요청을 반응하는 메서드를 생성했다. 이 클래스에서는 noteContent라고 하는 Map타입의 객체를 전달하고 있다. 애플리케이셔을 재가동한 후 다음 엔드포인트를 호출해 보겠다.
http://localhost:8080/actuator/note
{}보다시피 아직 값을 넣지 않은 상태라서 JSON 형태의 빈 값이 표현된다.
👀 TIP
스프링 부트 액추에이터의 자세한 내용은 공식 페이지에서 확인할 수 있다.
https://docs.spring.io/spring-boot/docs/current/reference/html/actuator.html
리미
728x90
'23-24 > Spring 1' 카테고리의 다른 글
| [스프링 1팀] 13장. 서비스 인증과 권한 부여 (2) | 2024.01.05 |
|---|---|
| [스프링 1팀] 12장. 서버 간 통신, [인프런] 섹션 0. 스프링 시큐리티 기본 (0) | 2023.12.29 |
| [스프링 1팀] 9장 연관관계 매핑 (1) | 2023.12.20 |
| [스프링 1팀] 8장 Spring Data JPA 활용 (2) | 2023.11.24 |
| [스프링1] 7장. 테스트 코드 작성하기 (0) | 2023.11.17 |